































































































































































































































Nat Mach Intell | 上海药物所提出ConfSeq,用"语言"读写三维分子构象
2026年6月11日,中国科学院上海药物研究所郑明月、张素林团队在Nature Machine Intelligence 在线发表题为“Bridging three-dimensional molecular structures and artificial intelligence with a conformation description language”的研究论文,报道了一种名为ConfSeq的分子构象描述语言。该方法可将三维分子构象编码为离散标记序列,从而把构象预测、从头三维分子生成、形状条件分子生成和三维分子表征学习等任务转化为序列建模问题,并在多个基准测试和药物发现案例中验证了方法的有效性。
以大语言模型为代表的人工智能技术正在推动多学科研究方法的发展。语言模型通过自监督学习从大规模标记序列中捕捉复杂模式,已在蛋白质、基因等序列建模任务中展现出应用价值。在化学与药物研发领域,化学语言模型(CLMs)通过将分子拓扑结构编码为SMILES、SELFIES等离散标记序列,支持二维分子生成、反应预测和分子表征学习等任务,郑明月团队此前开发的反应描述语言 ReactSeq 也是这一方向的探索之一。然而,分子性质和药物活性不仅取决于二维拓扑结构,也受到三维构象的影响。面向三维分子结构的有效表示与生成方法,是AI药物设计和新靶标创新药物研发中的关键技术。
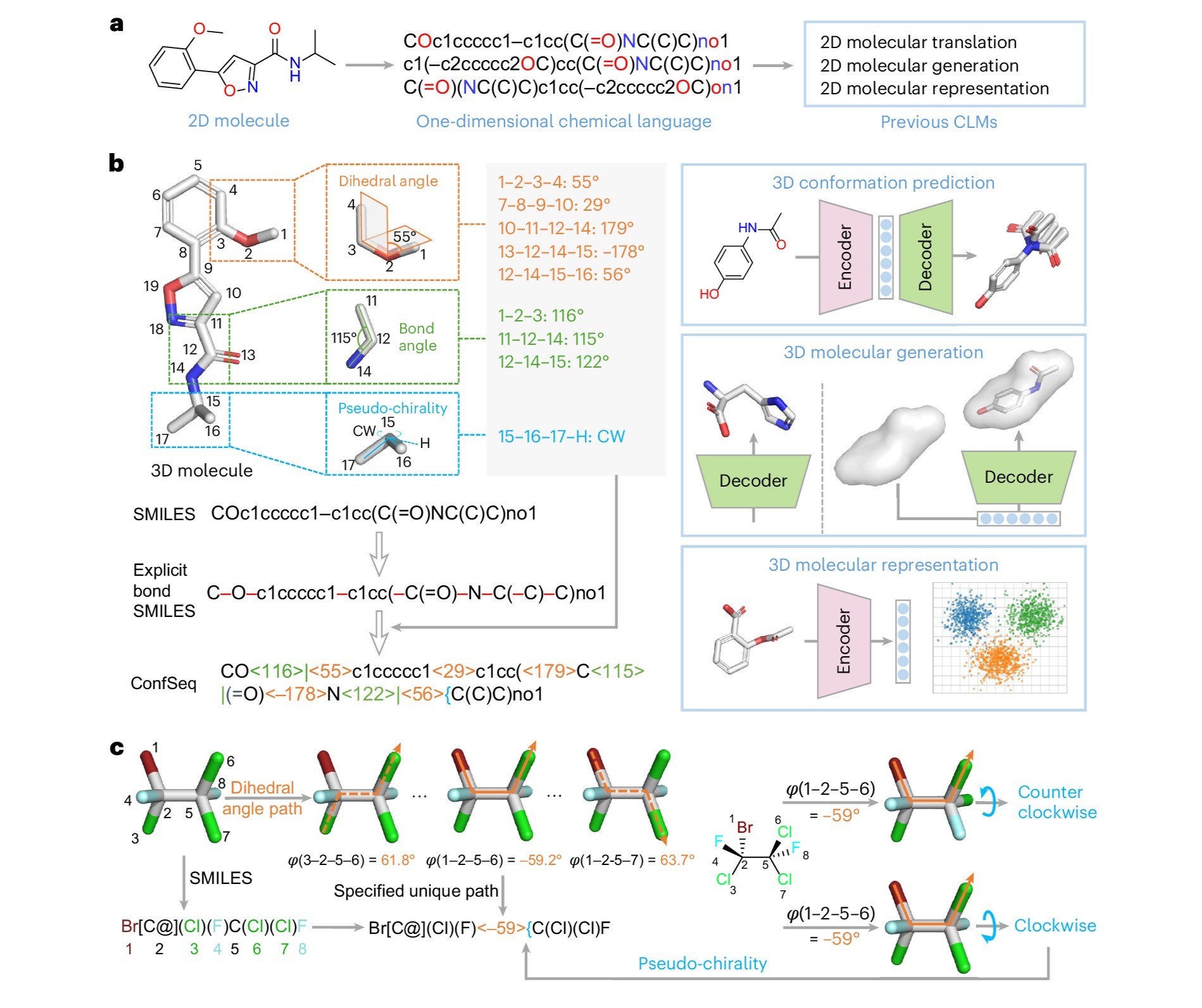
为解决上述问题,该研究开发了分子构象描述语言ConfSeq。ConfSeq利用二面角、键角和伪手性三类关键内坐标编码分子构象,将其离散化为标记并整合到SMILES框架中。借助ConfSeq,研究团队将构象预测、无条件与形状条件三维分子生成以及三维分子表征学习等任务,统一重构为序列建模问题。研究结果显示,基于标准Transformer架构的ConfSeq模型在多个基准数据集上取得了优于既有方法的表现,并可利用自回归生成概率为候选构象或生成分子提供评分参考。在药物发现应用中,研究团队进一步利用基于ConfSeq的三维表征开展基于配体的虚拟筛选,发现了多个新型STING抑制剂和ALDH1B1抑制剂。
该研究从分子表示方式入手,为语言模型处理三维分子任务提供了新的技术路径。相关结果表明,面向三维构象的序列化表示可作为AI药物设计关键技术体系的有益补充,为分子建模、虚拟筛选和候选分子发现提供新的计算工具。
上海药物所博士后熊嘉诚、博士生石宇琪,南昌大学与上海药物所联合培养硕士生吴敏为本文共同第一作者。上海药物所郑明月研究员、张素林研究员为本文共同通讯作者。本研究得到了国家自然科学基金、国家重点研发计划、中国科学院战略性先导科技专项、南京大学医药生物技术国家重点实验室开放基金、中国科学院青年创新促进会、上海市超级博士后激励计划和中国博士后科学基金会等项目资助。
全文链接:https://www.nature.com/articles/s42256-026-01250-8
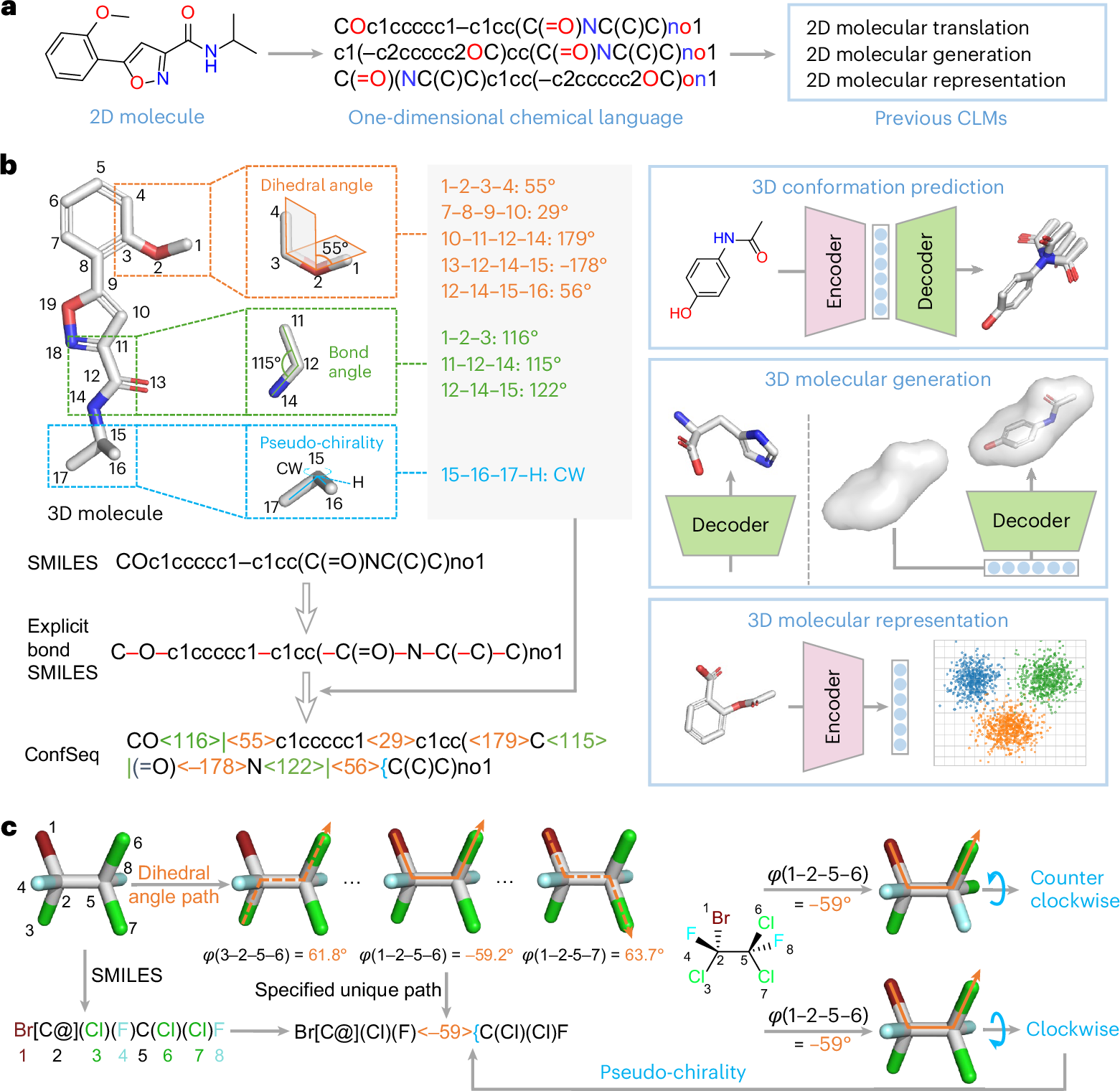
图. ConfSeq 将三维分子构象编码为离散标记序列,并用于构象预测、三维分子生成与三维表征学习等任务
(供稿部门:郑明月课题组;供稿人:熊嘉诚、石宇琪;审核:刁文桐;责编:宋文珂)